Hannover Messe is held annually in Hannover on the world’s largest exhibition grounds. This year’s fair highlighted key advancements in industrial development, with a strategic focus on Artificial Intelligence.
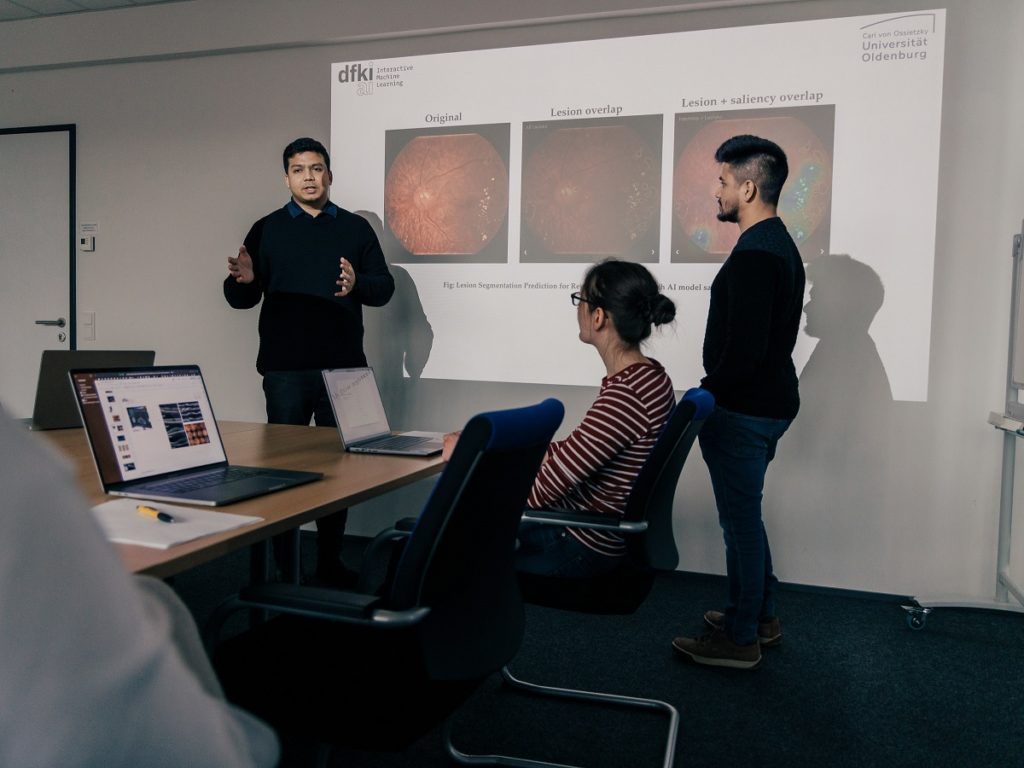
Representing the IML department at the DFKI booth, Robert Leist showcased the OphthalmoAI project alongside colleagues Siting Liang and Tuan Tran, and Professor Daniel Sonntag. The team demonstrated the OphthalmoCDSS prototype – a Clinical Decision Support System designed to assist ophthalmologists through three core AI functionalities: biomarker localization, disease progression forecasting, and treatment recommendations [1, 2].
The exhibit attracted high-profile interest, including visits from Rianne Letschert, the Dutch Minister of Education, Culture and Science; Ina Czyborra, Berlin’s Senator for Science, Health, and Care; and Bundestag members Tilman Kuban and Sebastian Lechner. Furthermore, DFKI CEO Antonio Krüger featured the prototype during an interview with Aktueller Bericht on Saarländischer Rundfunk.
At the well attended fair, the researchers were able to present their work and establish important industry contacts.
We are pleased to present a curated selection of our recent publications in the field of AI in medicine, highlighting our latest research, innovations, and contributions to advancing healthcare through intelligent technologies.
ECIR is one of the premier international conferences in the field of information retrieval with a competitive acceptance rate of around 23% in 2025, drawing leading researchers and practitioners from both academia and industry.
The study addresses a key limitation of deep learning in medical imaging: the lack of interpretability that hinders clinical adoption. Focusing on chest X-ray (CXR) imaging, the research introduces a novel framework that combines concept bottleneck models (CBMs) with a multi-agent retrieval-augmented generation (RAG) system for interpretable report generation. Unlike traditional deep learning models, the proposed CBM architecture incorporates a concept bottleneck layer by leveraging a multimodal biomedical vision-language model (VLMs) to learn a concept matrix that explicitly maps visual features to clinically meaningful concepts such as lung opacity, pleural effusion, or consolidation, thereby providing transparency into the decision-making process. These interpretable concept vectors are then used to guide a multi-agent RAG system, in which task-specific reasoning and acting (REACT) agents collaborate to retrieve relevant information and generate coherent, clinically grounded radiology reports. This approach enhances explainability, transparency, and trust, making it more suitable for real-world clinical environments. In addition to traditional evaluation metrics, the study adopts a LLM-as-a-judge methodology, employing five different large language models to assess the generated CXR reports in terms of semantic similarity, accuracy, correctness, clinical usefulness, and consistency.
The presented work at the ECIR 2025
The ECIR 2025 utilized several historic venues in Lucca, notably the San Francesco Church, which served as the primary location for keynotes and main sessions
In healthcare, language models are gaining increasing attention due to their ability to automatically process large amounts of unstructured or semi-structured data. “With their emergence, our interest in understanding their capabilities for tasks such as inference with natural language as a data basis is growing,” says scientist Siting Liang, who is advancing the AutoPrompt project in the Interactive Machine Learning research department at DFKI Lower Saxony. According to Liang, Natural Language Inference (NLI) is about determining “whether a statement is consistent with or contradicts the premise”. The AutoPrompt project runs from January to December 2024 and is funded by a grant from Accenture, one of the world’s leading consulting, technology and outsourcing companies.
Siting Liang explains her approach using an example. The starting point is the statement that patients with hemophilia are excluded from a study if certain premises apply, such as an increased risk of bleeding. “This task requires the models to understand the content of the statement, identify and extract relevant information from clinical trial data. The model evaluates whether the evidence supports, contradicts, or is neutral (i.e., neither supports nor contradicts) regarding the statement. Finally, based on the evaluation, the model infers the logical relationship between the statement and the evidence.” she explains.
Optimize the prompting
As a first step, the computational linguist wants to optimize the prompting, i.e. the instruction to the chatbot to receive a specific answer. To this end, she researches various strategies such as chain-of-thoughts methods. These involve giving instructions with intermediate steps that follow certain paths and trigger chains of thought. The aim is to elicit a certain degree of reasoning ability from the bot. “ChatGPT may be able to recognize relevant sentences from a context, but drawing precise logical inference requires a deeper understanding of domain knowledge and natural written language,” says Liang. In a second step, she will evaluate the performance of ChatGPT in NLI tasks using different datasets and suggest improvements. “Our goal is to provide the language models with more domain-specific sources as context,” she says. The goal is to implement the most suitable prompting strategies and a generation framework that enables more efficient access to additional knowledge.
Study with medical students
AI Human Collaboration, i.e. the collaboration between system and human, in this case medical students, plays a major role in the project. To this end, Siting Liang has set up a study within the project, for which she is currently looking for around ten participants. The given statement is that patients diagnosed with a malignant brain tumor are excluded from a primary study if criteria such as chemotherapy apply. The prospective participants are divided into two groups, within which they contribute their knowledge for two hours and make decisions comparing the statement with the clinical trial eligibility data. Group 1 evaluates the decisions of the AI system, and group 2 corrects errors of the system.
“If we want to improve AI systems, we need feedback from humans,” says Siting Liang, who has already worked with medical data in previous projects of the research department. Liang knows that systems can usually analyze medical texts and data very well: “But it is also possible that they hallucinate and give us wrong results. AutoPrompt is supposed to help achieve greater accuracy in the answers.”
The ‘AutoPrompt’ project was initiated at DFKI thanks to a grant from Accenture Labs. Dr. Bogdan E. Sacaleanu, Principal Director and Global AI Research Lead at Accenture Labs (on the right) and Prof. Dr. Daniel Sonntag, DFKI, have made the collaboration possible.
Artificial Intelligence will increasingly change our healthcare system. To prepare doctors for this change and involve them in the process, the German Medical Association (Bundesärztekammer) will develop a positioning on the Development of Artificial Intelligence in Healthcare (“Entwicklung der Künstlichen Intelligenz in der Gesundheitsversorgung”). The expert talks serve to accumulate and incorporate the perspectives of primarily non-medical stakeholders in the development of AI.
On 25 June 2024, Professor Sonntag gave a talk on AI in Patient Care and Medical Diagnostics (“KI in der Patientenversorgung und medizinischen Diagnostik”) as an invited expert. The positioning of the German Medical Association that needs to be developed includes the following questions in particular: What has been the focus of the use of AI in the last 5 years and which developments and fields of application of AI can be expected in your area of responsibility in the next three to five years? Which opportunities and risks/challenges do you see for the current and future use of AI in your area? Where do you see a need for regulation concerning the use of AI?
After three years, the Ophthalmo-AI project, which focused on intelligent, cooperative medical decision support in ophthalmology, was concluded in mid-March.
Four demonstrators (including an intelligent learning tool to support image diagnoses and a dashboard to support treatment decisions in therapy) were developed as part of the project and were evaluated very positively in the two participating clinics (Augenklinik Sulzbach, Augenzentrum am St. Franziskus-Hospital Münster).
In addition, two Master’s theses were completed as part of the project, with one completed and one planned employment of the students as IML employees in Oldenburg and Saarbrücken. Several publications have been published or submitted to AI and medical conferences, and a new project on active learning with Google Germany as a partner is based on the content of Ophthalmo-AI.
Hasan Md Tusfiqur Alam and Md Abdul Kadir from IML show project contents from Ophthalmo-AI to an audience. Photo by: Felix Brüggemann, Copyright: Google.
Research topics: Medical Text Analysis, Machine Learning & Deep Learning, LLMs
This research aims to investigate ChatGPT’s natural language inference (NLI) capabilities in healthcare contexts, focusing on tasks like understanding clinical trial information and evidence-based health fact-checking. We will explore various Chain-of-Thought methods to improve ChatGPT’s reasoning abilities and integrate dynamic context analysis techniques for better inference accuracy. Our approach involves integrating a retrieval-augmented generation framework, utilizing mechanisms such as context analysis, multi-hop reasoning, and knowledge retrieval.
Siting Liang from IML presents the Autoprompt Project
Duy Nguyen, from the Interactive Machine Learning department, and colleagues from the University of Oldenburg, Max Planck Research School for Intelligent Systems, the University of Texas at Austin, the University of California San Diego, and other institutions presented a full paper and a workshop paper at NeurIPS 2023. NeurIPS is considered one of the premier global conferences in the field of machine learning. The conference took place in New Orleans, USA, from December 10th to 16th, 2023, with an overall acceptance rate of 26.1%.
The first paper “LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching” introduces LVM-Med, a novel family of deep networks trained on a large-scale dataset of approximately 1.3 million medical images from 55 publicly available datasets (large vision model), encompassing various organs and modalities such as CT, MRI, X-ray, and Ultrasound. The authors address the challenge of domain shift between natural and medical images, proposing a self-supervised contrastive learning algorithm for fine-tuning pre-trained models. This algorithm integrates pair-wise image similarity metrics, captures structural constraints through a graph-matching loss function, and allows efficient end-to-end training using modern gradient estimation techniques. LVM-Med is evaluated on 15 medical tasks, demonstrating superior performance compared to state-of-the-art supervised, self-supervised, and foundation models. Notably, for challenging tasks like Brain Tumor Classification or Diabetic Retinopathy Grading, LVM-Med achieves a 6-7% improvement over previous vision-language models while using only a ResNet-50. Pre-trained models are made available to the community.
The second paper, “On the Out of Distribution Robustness of Foundation Models in Medical Image Segmentation”, accepted at the Workshop on robustness of zero/few-shot learning in foundation models (R0-FoMo), investigates the challenge of constructing robust models in medical imaging that can effectively generalize to test samples under distribution shifts. In particular, the authors compare the generalization performance of various pre-trained models after fine-tuning on the same in-distribution dataset, finding that foundation-based models exhibit better robustness than other architectures. The study also introduces a new Bayesian uncertainty estimation for frozen models, using it as an indicator to characterize the model’s performance on out-of-distribution (OOD) data, which proves beneficial for real-world applications. The experiments highlight the limitations of current indicators like accuracy on the line or agreement on the line, commonly used in natural image applications, and underscore the promise of the introduced Bayesian uncertainty, where lower uncertainty predictions tend to correspond to higher out-of-distribution (OOD) performance.
Like many previous NeurIPS conferences, NeurIPS-2023 this year features a diverse program with several invited speakers, 2,773 accepted posters, 14 tutorials, and 58 workshops. Among these, Duy reports important workshops for IML, for example, Foundation Models for Decision Making, Optimal Transport and Machine Learning, XAI in Action: Past, Present, and Future Applications, and Medical Imaging meets NeurIPS. Furthermore, our department connected and established collaboration for upcoming projects with leading groups in machine learning and bio-medical research at Harvard University and Stanford University.
Duy Nguyen with the poster explaining his paper at NeurIPS 2023
References
Nguyen, Duy MH, et al. “LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching.” arXiv preprint arXiv:2306.11925 (2023).
Nguyen, Duy MH, et al. “On the Out of Distribution Robustness of Foundation Models in Medical Image Segmentation.” arXiv preprint arXiv:2311.11096 (2023).
Research topics: Medical Image Analysis, Machine Learning & Deep Learning, Human-Machine-Interaction
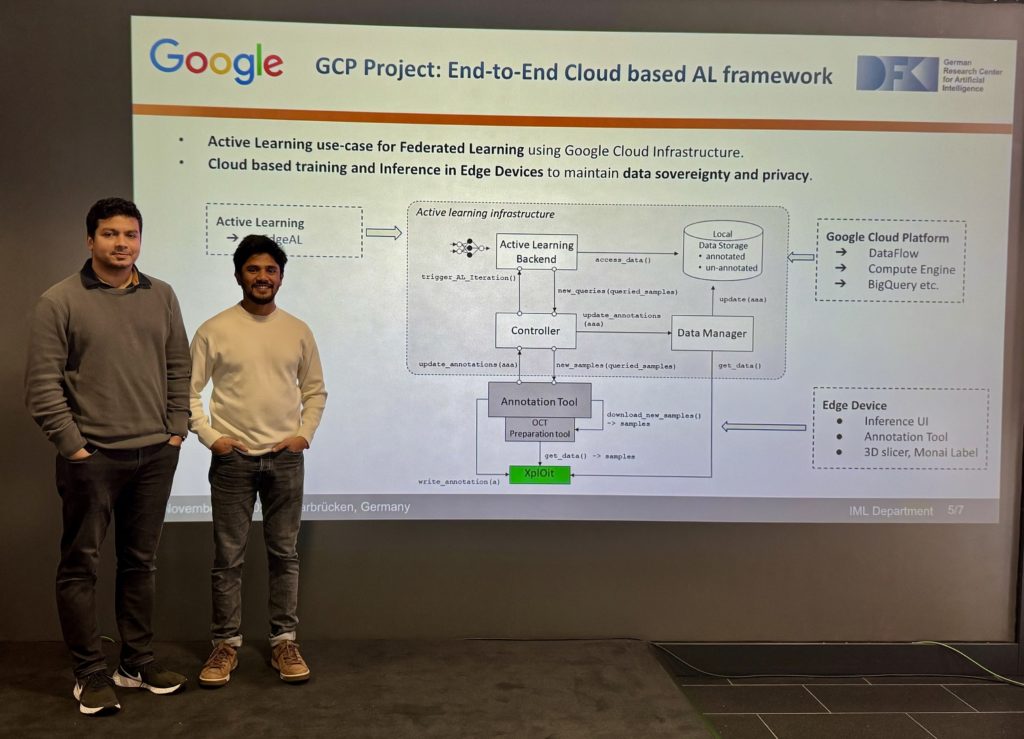
We develop a modularized active learning framework within the Google Cloud Platform, facilitating large-scale medical image annotation in a cost-effective manner while ensuring data sovereignty and privacy. Our work emphasizes a federated learning use case for healthcare data, taking into consideration data protection and security aspects. Our goal is to create an end-to-end platform for efficient annotation that benefits both clinicians and the research community.
Hasan Md Tusfiqur Alam (left) and Md Abdul Kadir from IML with their architecture for the GCP Project
The MICCAI Society is a professional organization dedicated to the fields of Medical Image Computing and Computer Assisted Interventions. It brings together researchers from various scientific disciplines such as computer science, robotics, physics, and medicine. The society is renowned for its annual MICCAI Conference, which allows for the presentation and publication of original research related to medical imaging. It has an acceptance rate of ~30%. Additionally, the society endorses and sponsors several scientific events each year.
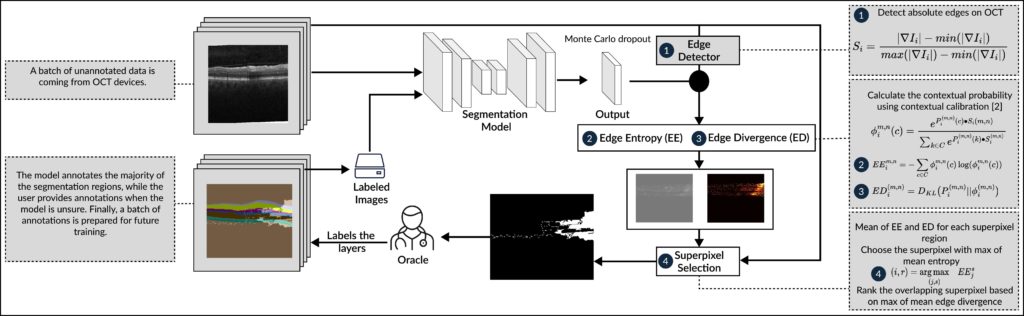
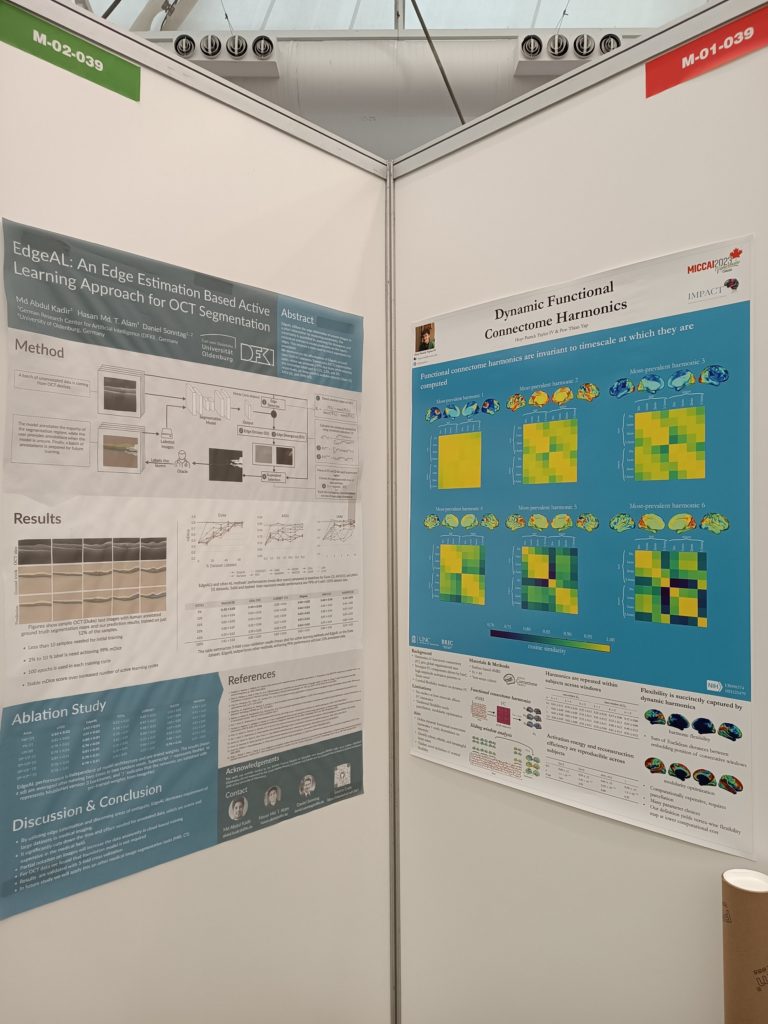
This year, a paper titled “EdgeAL: An Edge Estimation Based Active Learning Approach for OCT Segmentation” was presented by Md Abdul Kadir Hasan, Md Tusfiqur Alam, and Daniel Sonntag. The paper focuses on the use of active learning algorithms for training models with limited data. The authors propose EdgeAL, a method that uses the edge information of unseen images as a priori information to measure uncertainty. This uncertainty is quantified by analyzing the divergence and entropy in model predictions across edges. The measure is then used to select superpixels for annotation. The effectiveness of EdgeAL was demonstrated on multi-class Optical Coherence Tomography (OCT) segmentation tasks. The method achieved a 99% dice score while reducing the annotation label cost to 12%, 2.3%, and 3% on three publicly available datasets (Duke, AROI, and UMN). The source code for this method is available online.
Diagram from the paper “EdgeAL: An Edge Estimation Based Active Learning Approach for OCT Segmentation”
Md Abdul Kadir from IML at the MICCAI 2023 conference in Vancouver, Canada
Poster presenting IML’s work (on the left) at MICCAI 2023
References
Kadir, M.A., Alam, H.M.T., Sonntag, D. (2023). EdgeAL: An Edge Estimation Based Active Learning Approach for OCT Segmentation. In: Greenspan, H., et al. Medical Image Computing and Computer Assisted Intervention – MICCAI 2023. MICCAI 2023. Lecture Notes in Computer Science, vol 14221. Springer, Cham. https://doi.org/10.1007/978-3-031-43895-0_8
We are happy to announce that our work “TATL: Task Agnostic Transfer Learning for Skin Attributes Detection” has been accepted at the prestigious journal “Medical Image Analysis”. It’s a collaboration between DFKI, MPI, University of California (Berkeley) and Oldenburg University among others.
Existing skin attributes detection methods usually initialize with a pre-trained Imagenet network and then fine-tune on a medical target task. However, we argue that such approaches are suboptimal because medical datasets are largely different from ImageNet and often contain limited training samples.
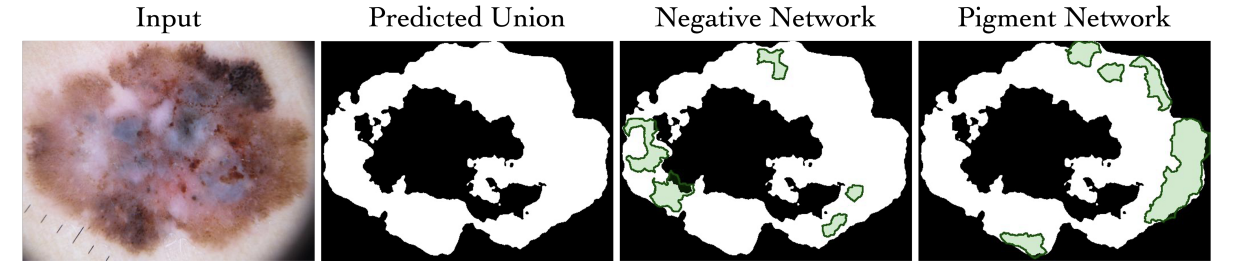
In this work, we propose Task Agnostic Transfer Learning (TATL), a novel framework motivated by dermatologists’ behaviors in the skincare context. Our method learns an attribute-agnostic segmenter that detects lesion skin regions and then transfers this knowledge to a set of attribute-specific classifiers to detect each particular attribute. Since TATL’s attribute-agnostic segmenter only detects skin attribute regions, it makes use of ample data from all attributes, allows transferring knowledge among features, and compensates for the lack of training data from rare attributes. The empirical results show that TATL not only works well with multiple architectures but also can achieve state-of-the-art performances while enjoying minimal model and computational complexities (30-50 times less than the number of parameters). We also provide theoretical insights and explanations for why our transfer learning framework performs well in practice.
The figure below demonstrates the usefulness of TATL when predicted lesion skin regions (predicted union) could cover both large regions as in Pigment Network and small disconnected regions as in Negative Network.