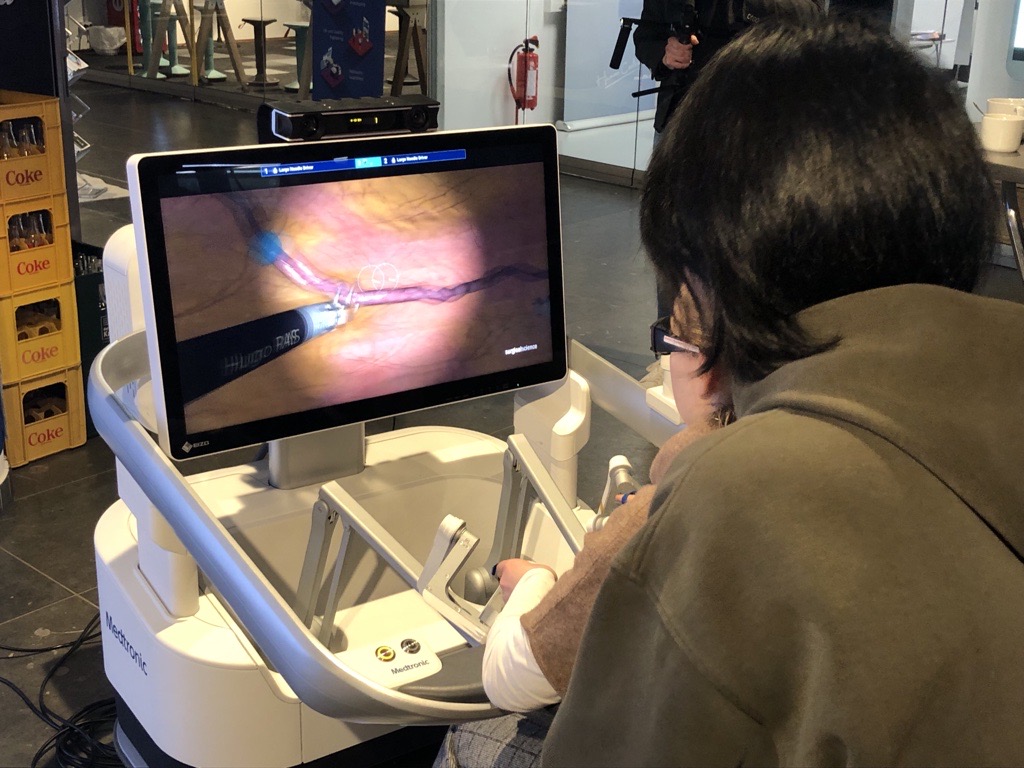
On November 21 and 22, 2025, the interdisciplinary congress InterSurge on the digital future of medicine, took place at the event location CORE in Oldenburg. Experts from medicine, science, technology, business, and politics came together to discuss new impulses for a sustainable healthcare system. Keynotes and presentations offered practical insights into current developments in AI, sustainability, and digital transformation. In workshops and hands-on sessions, participants discussed specific applications from areas such as AR, VR, and robotics—accompanied by live demonstrations and interactive formats.
The Interactive Machine Learning team presented its latest research in the CORE IML showroom through video demonstrations, offering visitors insights into innovative projects, including:
Ophthalmo AI – A Clinical Decision Support System to support ophthalmologists in the treatment of Diabetic Retinopathy and Age-related Macular Degeneration
CBM-RAG – an interactive system that leverages Explainable AI (XAI) and Multi-Agentic Retrieval-Augmented Generation (RAG) to enable transparent and trustworthy radiology report generation.
After three years, the Ophthalmo-AI project, which focused on intelligent, cooperative medical decision support in ophthalmology, was concluded in mid-March.
Four demonstrators (including an intelligent learning tool to support image diagnoses and a dashboard to support treatment decisions in therapy) were developed as part of the project and were evaluated very positively in the two participating clinics (Augenklinik Sulzbach, Augenzentrum am St. Franziskus-Hospital Münster).
In addition, two Master’s theses were completed as part of the project, with one completed and one planned employment of the students as IML employees in Oldenburg and Saarbrücken. Several publications have been published or submitted to AI and medical conferences, and a new project on active learning with Google Germany as a partner is based on the content of Ophthalmo-AI.
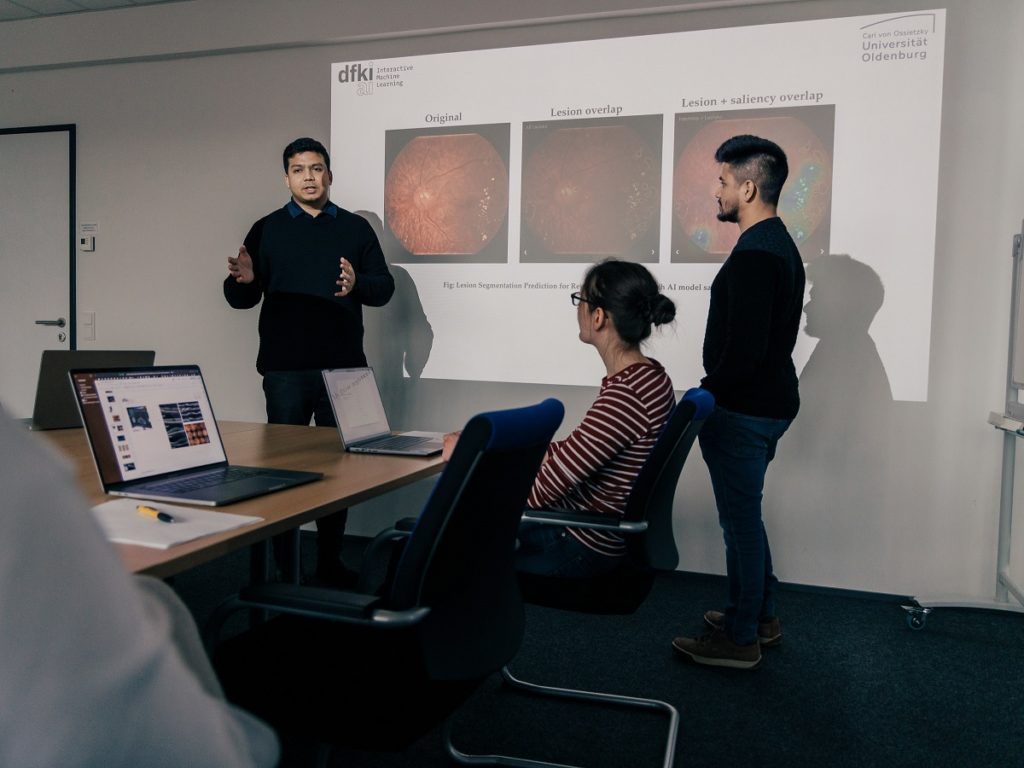
Hasan Md Tusfiqur Alam and Md Abdul Kadir from IML show project contents from Ophthalmo-AI to an audience. Photo by: Felix Brüggemann, Copyright: Google.
Duy Nguyen, from the Interactive Machine Learning department, and colleagues from the University of Oldenburg, Max Planck Research School for Intelligent Systems, the University of Texas at Austin, the University of California San Diego, and other institutions presented a full paper and a workshop paper at NeurIPS 2023. NeurIPS is considered one of the premier global conferences in the field of machine learning. The conference took place in New Orleans, USA, from December 10th to 16th, 2023, with an overall acceptance rate of 26.1%.
The first paper “LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching” introduces LVM-Med, a novel family of deep networks trained on a large-scale dataset of approximately 1.3 million medical images from 55 publicly available datasets (large vision model), encompassing various organs and modalities such as CT, MRI, X-ray, and Ultrasound. The authors address the challenge of domain shift between natural and medical images, proposing a self-supervised contrastive learning algorithm for fine-tuning pre-trained models. This algorithm integrates pair-wise image similarity metrics, captures structural constraints through a graph-matching loss function, and allows efficient end-to-end training using modern gradient estimation techniques. LVM-Med is evaluated on 15 medical tasks, demonstrating superior performance compared to state-of-the-art supervised, self-supervised, and foundation models. Notably, for challenging tasks like Brain Tumor Classification or Diabetic Retinopathy Grading, LVM-Med achieves a 6-7% improvement over previous vision-language models while using only a ResNet-50. Pre-trained models are made available to the community.
The second paper, “On the Out of Distribution Robustness of Foundation Models in Medical Image Segmentation”, accepted at the Workshop on robustness of zero/few-shot learning in foundation models (R0-FoMo), investigates the challenge of constructing robust models in medical imaging that can effectively generalize to test samples under distribution shifts. In particular, the authors compare the generalization performance of various pre-trained models after fine-tuning on the same in-distribution dataset, finding that foundation-based models exhibit better robustness than other architectures. The study also introduces a new Bayesian uncertainty estimation for frozen models, using it as an indicator to characterize the model’s performance on out-of-distribution (OOD) data, which proves beneficial for real-world applications. The experiments highlight the limitations of current indicators like accuracy on the line or agreement on the line, commonly used in natural image applications, and underscore the promise of the introduced Bayesian uncertainty, where lower uncertainty predictions tend to correspond to higher out-of-distribution (OOD) performance.
Like many previous NeurIPS conferences, NeurIPS-2023 this year features a diverse program with several invited speakers, 2,773 accepted posters, 14 tutorials, and 58 workshops. Among these, Duy reports important workshops for IML, for example, Foundation Models for Decision Making, Optimal Transport and Machine Learning, XAI in Action: Past, Present, and Future Applications, and Medical Imaging meets NeurIPS. Furthermore, our department connected and established collaboration for upcoming projects with leading groups in machine learning and bio-medical research at Harvard University and Stanford University.
Duy Nguyen with the poster explaining his paper at NeurIPS 2023
References
Nguyen, Duy MH, et al. “LVM-Med: Learning Large-Scale Self-Supervised Vision Models for Medical Imaging via Second-order Graph Matching.” arXiv preprint arXiv:2306.11925 (2023).
Nguyen, Duy MH, et al. “On the Out of Distribution Robustness of Foundation Models in Medical Image Segmentation.” arXiv preprint arXiv:2311.11096 (2023).
The MICCAI Society is a professional organization dedicated to the fields of Medical Image Computing and Computer Assisted Interventions. It brings together researchers from various scientific disciplines such as computer science, robotics, physics, and medicine. The society is renowned for its annual MICCAI Conference, which allows for the presentation and publication of original research related to medical imaging. It has an acceptance rate of ~30%. Additionally, the society endorses and sponsors several scientific events each year.
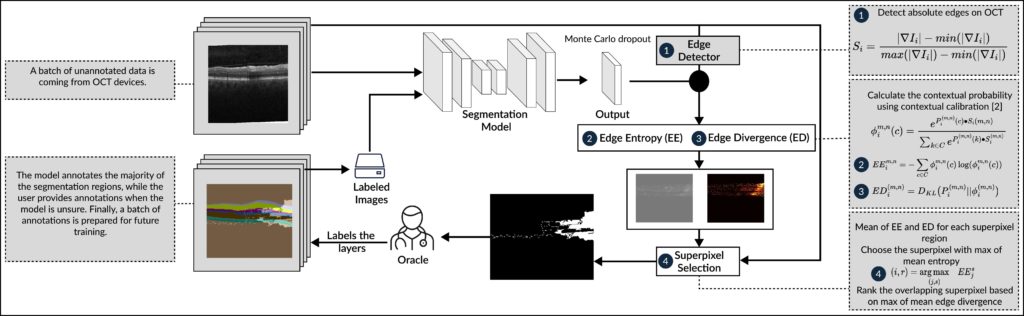
This year, a paper titled “EdgeAL: An Edge Estimation Based Active Learning Approach for OCT Segmentation” was presented by Md Abdul Kadir Hasan, Md Tusfiqur Alam, and Daniel Sonntag. The paper focuses on the use of active learning algorithms for training models with limited data. The authors propose EdgeAL, a method that uses the edge information of unseen images as a priori information to measure uncertainty. This uncertainty is quantified by analyzing the divergence and entropy in model predictions across edges. The measure is then used to select superpixels for annotation. The effectiveness of EdgeAL was demonstrated on multi-class Optical Coherence Tomography (OCT) segmentation tasks. The method achieved a 99% dice score while reducing the annotation label cost to 12%, 2.3%, and 3% on three publicly available datasets (Duke, AROI, and UMN). The source code for this method is available online.
Diagram from the paper “EdgeAL: An Edge Estimation Based Active Learning Approach for OCT Segmentation”
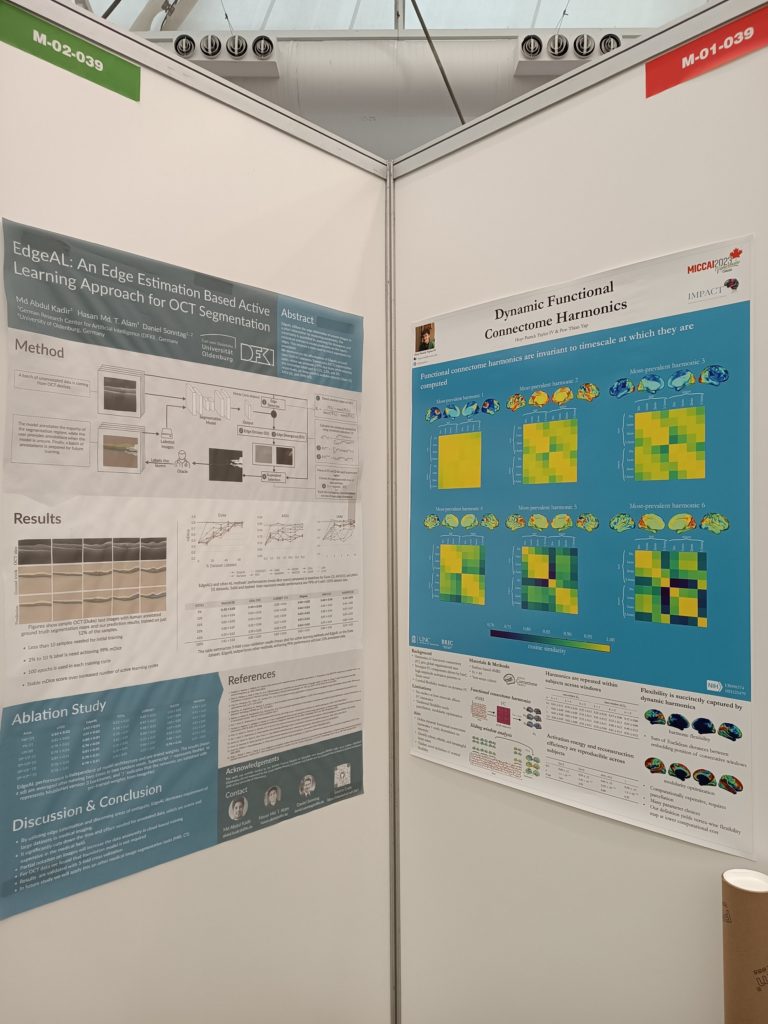
Md Abdul Kadir from IML at the MICCAI 2023 conference in Vancouver, Canada
Poster presenting IML’s work (on the left) at MICCAI 2023
References
Kadir, M.A., Alam, H.M.T., Sonntag, D. (2023). EdgeAL: An Edge Estimation Based Active Learning Approach for OCT Segmentation. In: Greenspan, H., et al. Medical Image Computing and Computer Assisted Intervention – MICCAI 2023. MICCAI 2023. Lecture Notes in Computer Science, vol 14221. Springer, Cham. https://doi.org/10.1007/978-3-031-43895-0_8