On November 21 and 22, 2025, the interdisciplinary congress InterSurge on the digital future of medicine, took place at the event location CORE in Oldenburg. Experts from medicine, science, technology, business, and politics came together to discuss new impulses for a sustainable healthcare system. Keynotes and presentations offered practical insights into current developments in AI, sustainability, and digital transformation. … Continue reading →
We are pleased to present a curated selection of our recent publications in the field of AI in medicine, highlighting our latest research, innovations, and contributions to advancing healthcare through intelligent technologies. Towards Interpretable Radiology Report Generation via Concept Bottlenecks Using a Multi-agentic RAG CBM-RAG: Demonstrating Enhanced Interpretability in Radiology Report Generation with Multi-Agent RAG … Continue reading →
Hasan Alam from the Interactive Machine Learning (IML) Department at DFKI presented our paper, “Towards Interpretable Radiology Report Generation via Concept Bottlenecks using a Multi-Agentic RAG”, at the 47th European Conference on Information Retrieval (ECIR 2025), held from April 6–10, 2025 in Lucca, Italy. ECIR is one of the premier international conferences in the field … Continue reading →
In healthcare, language models are gaining increasing attention due to their ability to automatically process large amounts of unstructured or semi-structured data. “With their emergence, our interest in understanding their capabilities for tasks such as inference with natural language as a data basis is growing,” says scientist Siting Liang, who is advancing the AutoPrompt project … Continue reading →
Artificial Intelligence will increasingly change our healthcare system. To prepare doctors for this change and involve them in the process, the German Medical Association (Bundesärztekammer) will develop a positioning on the Development of Artificial Intelligence in Healthcare (“Entwicklung der Künstlichen Intelligenz in der Gesundheitsversorgung”). The expert talks serve to accumulate and incorporate the perspectives of … Continue reading →
After three years, the Ophthalmo-AI project, which focused on intelligent, cooperative medical decision support in ophthalmology, was concluded in mid-March. Four demonstrators (including an intelligent learning tool to support image diagnoses and a dashboard to support treatment decisions in therapy) were developed as part of the project and were evaluated very positively in the two … Continue reading →
This research aims to investigate ChatGPT’s natural language inference (NLI) capabilities in healthcare contexts, focusing on tasks like understanding clinical trial information and evidence-based health fact-checking. We will explore various Chain-of-Thought methods to improve ChatGPT’s reasoning abilities and integrate dynamic context analysis techniques for better inference accuracy. Our approach involves integrating a retrieval-augmented generation framework, … Continue reading →
Duy Nguyen, from the Interactive Machine Learning department, and colleagues from the University of Oldenburg, Max Planck Research School for Intelligent Systems, the University of Texas at Austin, the University of California San Diego, and other institutions presented a full paper and a workshop paper at NeurIPS 2023. NeurIPS is considered one of the premier … Continue reading →
We develop a modularized active learning framework within the Google Cloud Platform, facilitating large-scale medical image annotation in a cost-effective manner while ensuring data sovereignty and privacy. Our work emphasizes a federated learning use case for healthcare data, taking into consideration data protection and security aspects. Our goal is to create an end-to-end platform for … Continue reading →
The MICCAI Society is a professional organization dedicated to the fields of Medical Image Computing and Computer Assisted Interventions. It brings together researchers from various scientific disciplines such as computer science, robotics, physics, and medicine. The society is renowned for its annual MICCAI Conference, which allows for the presentation and publication of original research related … Continue reading →
We are happy to announce that our work “TATL: Task Agnostic Transfer Learning for Skin Attributes Detection” has been accepted at the prestigious journal “Medical Image Analysis”. It’s a collaboration between DFKI, MPI, University of California (Berkeley) and Oldenburg University among others. Existing skin attributes detection methods usually initialize with a pre-trained Imagenet network and … Continue reading →
Article with Professor Sonntag’s contributions of ideas at Transformation Leader (in German) Reference: Bensch, Hendrik (2021): Disruption, Globale Basis, KI in der Medizin. In: Transformation Leader, Ausgabe 3/2021, S. 65-69. PDF (https://transformationleader.de/es-fehlt-an-globalen-datensaetzen-um-zu-bestimmten-krankheiten-eine-ki-zu-trainieren/)
pAItient: The Management & Krankenhaus journal features an interview with Daniel Sonntag about the detection of Covid-19 based on CT scans, and medical decision support in clinical practice.
Ophthalmo-AI: Virtual Kick-off of the Ophthalmo-AI project (BMBF) in Saarbrücken, Sulzbach, Münster, Berlin and Heidelberg. In Ophthalmo-AI we aim at developing better diagnostic and therapeutic decision support in ophthalmology through effective collaboration of machine and human expertise (Interactive Machine Learning – IML).
Double or nothing – Alexander Prange will present a paper on “Assessing Cognitive Test Performance Using Automatic Digital Pen Features Analysis” at this year’s ACM UMAP conference on User Modeling, Adaptation and Personalization. In contrast to the paper presented at this year’s CHI, we analyze cognitive assessments solely based on digital pen features, without additional … Continue reading →
Duy Nguyen presents “An Attention Mechanism using Multiple Knowledge Sources for COVID-19 Detection from CT Images” at the AAAI’21. This research is part of the pAItient project.
Alexander Prange will present a paper on “Explainable Automatic Evaluation of the Trail Making Test for Dementia Screening” at this year’s CHI conference. As part of the interactive cognitive assessment tool we generate automatic and explainable structured reports of cognitive assessments that were recorded with a digital pen.
An interview with Daniel Sonntag about “AI for healthy living” has been published in a German digital healthcare campaign, see https://issuu.com/europeanmediapartner/docs/analyse__-_digi_gesundheit_it-sec_18122020_epaper (in German)
The German Standardization Roadmap Artificial Intelligence has been published recently in November 2020. In medicine, secure framework conditions have to be created; and the legal context, economy, technical aspects, acceptance, privacy, data security, and ethical aspects have to be taken into account. In the pAItient project, where DFKI is responsible for secure framework conditions of … Continue reading →
pAItient: Virtual Kick-Off of the pAItient project (BMG) in Saarbrücken and Heidelberg. In pAItient we aim at automating the development of AI-based approaches in medicine (from the idea to translation into cross-site clinical routine).
Invited panel discussion as a Webinar, organised by the Konrad Adenauer Stiftung, on AI against COVID-19 with experts from China. Webinars on Innovation in Health Governance and AI-related Technologies During the COVID-19 Pandemic Flyer Related editorial of the German Journal of Artificial Intelligence Sponsored by:
KI-Para-Mi: Kick-off of the KI-Para-Mi Project (BMBF) as webinar in Munich and Saarbrücken. In KI-Para-Mi, we develop an intelligent personnel planning system for flexible shift scheduling in nursing, which above all takes into account the interests of the employees.
Daniel Sonntag is an invited speaker at the AAAI Fall Symposium Series, Human-Centered AI: Trustworthiness of AI Models & Data. Title: “Interactive Machine Learning and Explainable AI, two sides of the same coin.”
 Hasan Alam from the Interactive Machine Learning (IML) Department at DFKI presented our paper, “Towards Interpretable Radiology Report Generation via Concept Bottlenecks using a Multi-Agentic RAG”, at the 47th European Conference on Information Retrieval (ECIR 2025), held from April 6–10, 2025 in Lucca, Italy. ECIR is one of the premier international conferences in the field … Continue reading
Hasan Alam from the Interactive Machine Learning (IML) Department at DFKI presented our paper, “Towards Interpretable Radiology Report Generation via Concept Bottlenecks using a Multi-Agentic RAG”, at the 47th European Conference on Information Retrieval (ECIR 2025), held from April 6–10, 2025 in Lucca, Italy. ECIR is one of the premier international conferences in the field … Continue reading In healthcare, language models are gaining increasing attention due to their ability to automatically process large amounts of unstructured or semi-structured data. “With their emergence, our interest in understanding their capabilities for tasks such as inference with natural language as a data basis is growing,” says scientist Siting Liang, who is advancing the AutoPrompt project … Continue reading
In healthcare, language models are gaining increasing attention due to their ability to automatically process large amounts of unstructured or semi-structured data. “With their emergence, our interest in understanding their capabilities for tasks such as inference with natural language as a data basis is growing,” says scientist Siting Liang, who is advancing the AutoPrompt project … Continue reading Artificial Intelligence will increasingly change our healthcare system. To prepare doctors for this change and involve them in the process, the German Medical Association (Bundesärztekammer) will develop a positioning on the Development of Artificial Intelligence in Healthcare (“Entwicklung der Künstlichen Intelligenz in der Gesundheitsversorgung”). The expert talks serve to accumulate and incorporate the perspectives of … Continue reading
Artificial Intelligence will increasingly change our healthcare system. To prepare doctors for this change and involve them in the process, the German Medical Association (Bundesärztekammer) will develop a positioning on the Development of Artificial Intelligence in Healthcare (“Entwicklung der Künstlichen Intelligenz in der Gesundheitsversorgung”). The expert talks serve to accumulate and incorporate the perspectives of … Continue reading After three years, the Ophthalmo-AI project, which focused on intelligent, cooperative medical decision support in ophthalmology, was concluded in mid-March. Four demonstrators (including an intelligent learning tool to support image diagnoses and a dashboard to support treatment decisions in therapy) were developed as part of the project and were evaluated very positively in the two … Continue reading
After three years, the Ophthalmo-AI project, which focused on intelligent, cooperative medical decision support in ophthalmology, was concluded in mid-March. Four demonstrators (including an intelligent learning tool to support image diagnoses and a dashboard to support treatment decisions in therapy) were developed as part of the project and were evaluated very positively in the two … Continue reading This research aims to investigate ChatGPT’s natural language inference (NLI) capabilities in healthcare contexts, focusing on tasks like understanding clinical trial information and evidence-based health fact-checking. We will explore various Chain-of-Thought methods to improve ChatGPT’s reasoning abilities and integrate dynamic context analysis techniques for better inference accuracy. Our approach involves integrating a retrieval-augmented generation framework, … Continue reading
This research aims to investigate ChatGPT’s natural language inference (NLI) capabilities in healthcare contexts, focusing on tasks like understanding clinical trial information and evidence-based health fact-checking. We will explore various Chain-of-Thought methods to improve ChatGPT’s reasoning abilities and integrate dynamic context analysis techniques for better inference accuracy. Our approach involves integrating a retrieval-augmented generation framework, … Continue reading Duy Nguyen, from the Interactive Machine Learning department, and colleagues from the University of Oldenburg, Max Planck Research School for Intelligent Systems, the University of Texas at Austin, the University of California San Diego, and other institutions presented a full paper and a workshop paper at NeurIPS 2023. NeurIPS is considered one of the premier … Continue reading
Duy Nguyen, from the Interactive Machine Learning department, and colleagues from the University of Oldenburg, Max Planck Research School for Intelligent Systems, the University of Texas at Austin, the University of California San Diego, and other institutions presented a full paper and a workshop paper at NeurIPS 2023. NeurIPS is considered one of the premier … Continue reading We develop a modularized active learning framework within the Google Cloud Platform, facilitating large-scale medical image annotation in a cost-effective manner while ensuring data sovereignty and privacy. Our work emphasizes a federated learning use case for healthcare data, taking into consideration data protection and security aspects. Our goal is to create an end-to-end platform for … Continue reading
We develop a modularized active learning framework within the Google Cloud Platform, facilitating large-scale medical image annotation in a cost-effective manner while ensuring data sovereignty and privacy. Our work emphasizes a federated learning use case for healthcare data, taking into consideration data protection and security aspects. Our goal is to create an end-to-end platform for … Continue reading The MICCAI Society is a professional organization dedicated to the fields of Medical Image Computing and Computer Assisted Interventions. It brings together researchers from various scientific disciplines such as computer science, robotics, physics, and medicine. The society is renowned for its annual MICCAI Conference, which allows for the presentation and publication of original research related … Continue reading
The MICCAI Society is a professional organization dedicated to the fields of Medical Image Computing and Computer Assisted Interventions. It brings together researchers from various scientific disciplines such as computer science, robotics, physics, and medicine. The society is renowned for its annual MICCAI Conference, which allows for the presentation and publication of original research related … Continue reading We are happy to announce that our work “TATL: Task Agnostic Transfer Learning for Skin Attributes Detection” has been accepted at the prestigious journal “Medical Image Analysis”. It’s a collaboration between DFKI, MPI, University of California (Berkeley) and Oldenburg University among others. Existing skin attributes detection methods usually initialize with a pre-trained Imagenet network and … Continue reading
We are happy to announce that our work “TATL: Task Agnostic Transfer Learning for Skin Attributes Detection” has been accepted at the prestigious journal “Medical Image Analysis”. It’s a collaboration between DFKI, MPI, University of California (Berkeley) and Oldenburg University among others. Existing skin attributes detection methods usually initialize with a pre-trained Imagenet network and … Continue reading Article with Professor Sonntag’s contributions of ideas at Transformation Leader (in German) Reference: Bensch, Hendrik (2021): Disruption, Globale Basis, KI in der Medizin. In: Transformation Leader, Ausgabe 3/2021, S. 65-69. PDF (https://transformationleader.de/es-fehlt-an-globalen-datensaetzen-um-zu-bestimmten-krankheiten-eine-ki-zu-trainieren/)
Article with Professor Sonntag’s contributions of ideas at Transformation Leader (in German) Reference: Bensch, Hendrik (2021): Disruption, Globale Basis, KI in der Medizin. In: Transformation Leader, Ausgabe 3/2021, S. 65-69. PDF (https://transformationleader.de/es-fehlt-an-globalen-datensaetzen-um-zu-bestimmten-krankheiten-eine-ki-zu-trainieren/) pAItient: The Management & Krankenhaus journal features an interview with Daniel Sonntag about the detection of Covid-19 based on CT scans, and medical decision support in clinical practice.
pAItient: The Management & Krankenhaus journal features an interview with Daniel Sonntag about the detection of Covid-19 based on CT scans, and medical decision support in clinical practice. Ophthalmo-AI: Virtual Kick-off of the Ophthalmo-AI project (BMBF) in Saarbrücken, Sulzbach, Münster, Berlin and Heidelberg. In Ophthalmo-AI we aim at developing better diagnostic and therapeutic decision support in ophthalmology through effective collaboration of machine and human expertise (Interactive Machine Learning – IML).
Ophthalmo-AI: Virtual Kick-off of the Ophthalmo-AI project (BMBF) in Saarbrücken, Sulzbach, Münster, Berlin and Heidelberg. In Ophthalmo-AI we aim at developing better diagnostic and therapeutic decision support in ophthalmology through effective collaboration of machine and human expertise (Interactive Machine Learning – IML). Double or nothing – Alexander Prange will present a paper on “Assessing Cognitive Test Performance Using Automatic Digital Pen Features Analysis” at this year’s ACM UMAP conference on User Modeling, Adaptation and Personalization. In contrast to the paper presented at this year’s CHI, we analyze cognitive assessments solely based on digital pen features, without additional … Continue reading
Double or nothing – Alexander Prange will present a paper on “Assessing Cognitive Test Performance Using Automatic Digital Pen Features Analysis” at this year’s ACM UMAP conference on User Modeling, Adaptation and Personalization. In contrast to the paper presented at this year’s CHI, we analyze cognitive assessments solely based on digital pen features, without additional … Continue reading An interview with Daniel Sonntag about “AI for healthy living” has been published in a German digital healthcare campaign, see https://issuu.com/europeanmediapartner/docs/analyse__-_digi_gesundheit_it-sec_18122020_epaper (in German)
An interview with Daniel Sonntag about “AI for healthy living” has been published in a German digital healthcare campaign, see https://issuu.com/europeanmediapartner/docs/analyse__-_digi_gesundheit_it-sec_18122020_epaper (in German)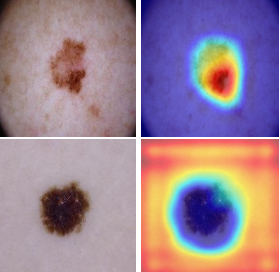 The German Standardization Roadmap Artificial Intelligence has been published recently in November 2020. In medicine, secure framework conditions have to be created; and the legal context, economy, technical aspects, acceptance, privacy, data security, and ethical aspects have to be taken into account. In the pAItient project, where DFKI is responsible for secure framework conditions of … Continue reading
The German Standardization Roadmap Artificial Intelligence has been published recently in November 2020. In medicine, secure framework conditions have to be created; and the legal context, economy, technical aspects, acceptance, privacy, data security, and ethical aspects have to be taken into account. In the pAItient project, where DFKI is responsible for secure framework conditions of … Continue reading Invited panel discussion as a Webinar, organised by the Konrad Adenauer Stiftung, on AI against COVID-19 with experts from China. Webinars on Innovation in Health Governance and AI-related Technologies During the COVID-19 Pandemic Flyer Related editorial of the German Journal of Artificial Intelligence Sponsored by:
Invited panel discussion as a Webinar, organised by the Konrad Adenauer Stiftung, on AI against COVID-19 with experts from China. Webinars on Innovation in Health Governance and AI-related Technologies During the COVID-19 Pandemic Flyer Related editorial of the German Journal of Artificial Intelligence Sponsored by: KI-Para-Mi: Kick-off of the KI-Para-Mi Project (BMBF) as webinar in Munich and Saarbrücken. In KI-Para-Mi, we develop an intelligent personnel planning system for flexible shift scheduling in nursing, which above all takes into account the interests of the employees.
KI-Para-Mi: Kick-off of the KI-Para-Mi Project (BMBF) as webinar in Munich and Saarbrücken. In KI-Para-Mi, we develop an intelligent personnel planning system for flexible shift scheduling in nursing, which above all takes into account the interests of the employees. Daniel Sonntag is an invited speaker at the AAAI Fall Symposium Series, Human-Centered AI: Trustworthiness of AI Models & Data. Title: “Interactive Machine Learning and Explainable AI, two sides of the same coin.”
Daniel Sonntag is an invited speaker at the AAAI Fall Symposium Series, Human-Centered AI: Trustworthiness of AI Models & Data. Title: “Interactive Machine Learning and Explainable AI, two sides of the same coin.”